Variational Autoencoders

A Variational Autoencoder (VAE) is a generative model that learns a probabilistic latent representation of input data. Unlike traditional autoencoders, which focus solely on reconstructing the input, VAEs aim to capture the underlying structure and variability of the data. This is achieved by learning a continuous probability distribution (typically Gaussian) over the latent space. By encoding input data into this distribution rather than a fixed point, VAEs can generate new, diverse, and realistic data points by sampling from the learned distribution. This capability makes VAEs valuable for tasks such as image synthesis, data augmentation, and anomaly detection. Moreover, the continuous nature of the latent space enables meaningful interpolation between data points.
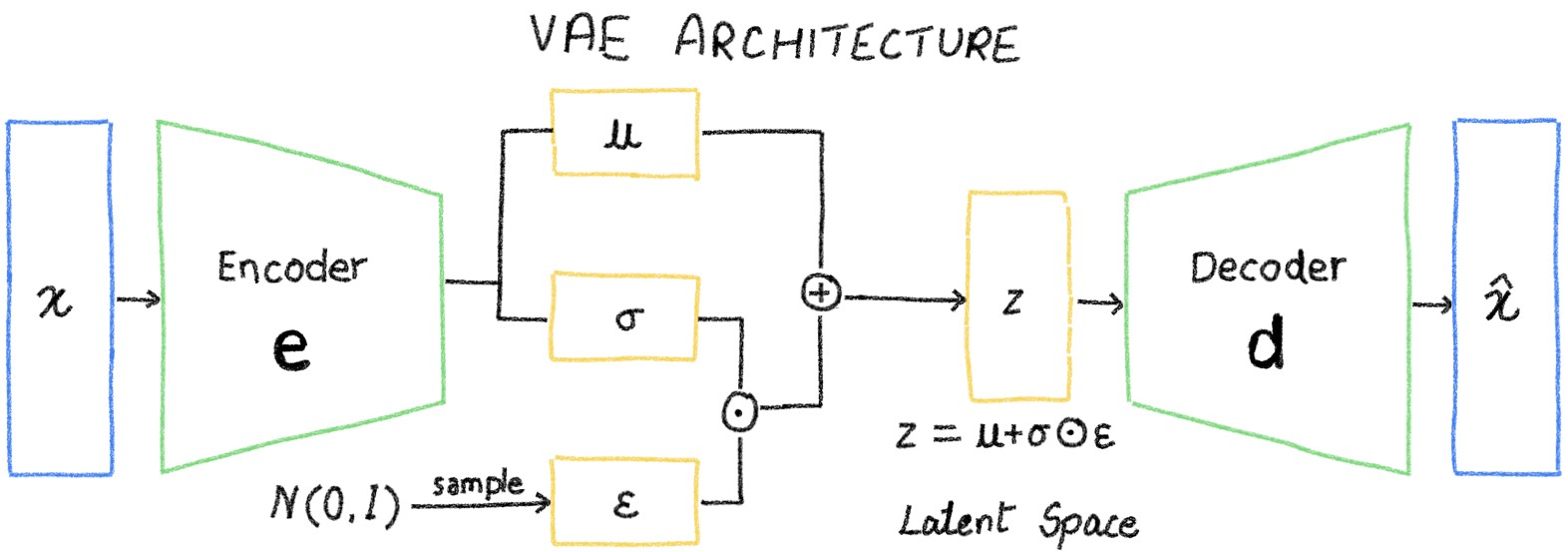
A Variational Autoencoder (VAE) is a machine learning model that generates new data by learning to compress and decompress information. Unlike traditional autoencoders, VAEs don't just learn to copy data; they learn to understand the underlying structure and patterns.
How does it work?
- Encoding: The VAE first transforms input data into a simplified representation, called a latent code.
- Latent Space: This latent code exists in a smaller, compressed space, making it easier to analyze and manipulate.
- Decoding: Finally, the VAE uses the latent code to reconstruct the original data.
The key difference: VAEs don't just learn one specific encoding for each piece of data; they learn a range of possibilities, represented as probability distributions. This flexibility allows them to generate new, realistic data that's similar to the training data.

Let's start with the basics: the autoencoder. Think of it as a machine that learns to shrink and expand images. It takes an image, compresses it into a smaller code, and then tries to rebuild the original image from that code. This smaller code is like a secret message about the image.
Now, imagine this secret message is stored in a warehouse filled with boxes. Each box holds a different type of image, like dogs, cats, or zebras. The problem is, only the machine knows which box is which!
When we ask the machine to create a new image, it's like randomly picking a box from the warehouse. Sometimes, we get lucky and find the right box for the image we want. But most of the time, we end up with a box of nonsense, resulting in a blurry or strange image.

So, how do we fix the problems with regular autoencoders? That's where the Variational Autoencoder, or VAE, comes in.
Imagine building a fence around the useful parts of the latent space. This fenced-in area is where we want our data to live. The VAE's job is to figure out where to put the blueprints for things like dogs, cats, and giraffes inside this fence.
Once the VAE has learned this, we can randomly pick a spot within the fence and ask it to create an image. Since the whole fence is filled with useful information, no matter where we pick, we'll get a realistic image. That's the magic of VAEs!
VAEs have a special ability: images that are similar are placed close together on this map. This means that if you're looking at an image of a dog and take a small step in any direction, you'll still see an image of something dog-like. This is super important because it means we can explore new areas of the map and still get meaningful images. Regular autoencoders can't do this.
For example, if the coordinates (100,900) represent a dog image, then nearby coordinates like (100.5,900.7) will also likely represent dog-like images.

To better understand the difference between AE and VAE latent spaces:
- AE learns to compress data, but VAE learns to both compress and create new data.
- AE can't make new things, but VAE can generate new images.
- AE might not make a shirt if you change the input a little, but VAE can make shirts with slight variations.
Optimization:
- AE tries to copy the original data as closely as possible.
- VAE tries to both copy the original data and make sure the new data is realistic.

Imagine a hidden, multi-dimensional space where we can represent images. In this space, each image is like a fuzzy, spherical cloud. The center of this cloud is the mean vector, and its size and shape are determined by the standard deviation.
The Mean Vector and Standard Deviation
- Mean Vector: This is the central point of the cloud. It represents the most likely or average representation of the image in this hidden space. Think of it as the image's "core" or essence.
- Standard Deviation: This is a measure of how spread out the cloud is. A small standard deviation means the image is tightly clustered around its mean vector, indicating a more precise representation. A larger standard deviation means the image can be represented in various ways, allowing for more flexibility and creativity.
The Multivariate Normal Distribution
When we combine all these fuzzy clouds for every image, we get a multivariate normal distribution (MND). This MND is a complex mathematical object that describes how images are related to each other in this hidden space. It helps the VAE understand the underlying structure and patterns in the data.
Key Points:
- Each image has its own unique cloud (distribution) in the latent space.
- The mean vector determines the center of the cloud, representing the core of the image.
- The standard deviation determines the spread or fuzziness of the cloud, indicating the range of possible representations.
- The collection of all these clouds forms a multivariate normal distribution, which captures the relationships between images.
By understanding these concepts, we can better appreciate how VAEs learn and generate new data, and how they can be used for various applications such as image generation, denoising, and anomaly detection.

A multivariate normal distribution is a statistical model that represents the joint probability of several normally distributed random variables. Unlike a univariate normal distribution, which describes a single variable, a multivariate normal distribution considers the relationships and dependencies between multiple variables.
Imagine you have a collection of random variables, let's call them X₁, X₂, ..., Xₖ. Each of these variables follows a normal distribution with its own mean (μ₁, μ₂, ..., μₖ) and variance (𝝈²₁, 𝝈²₂, ..., 𝝈²ₖ). If these variables are independent (meaning their values don't influence each other), then their joint probability distribution can be described by a multivariate normal distribution.
The probability density function (PDF) of this joint distribution is denoted as fx(X). It essentially gives you the likelihood of observing a particular set of values for X₁, X₂, ..., Xₖ.

A multivariate normal distribution (MND) can be visualized as a multidimensional bell curve. Imagine a bell-shaped curve stretched out in multiple directions, rather than just one. The center of this multidimensional bell curve is determined by a mean vector.
Think of an MND as a cloud of points scattered throughout a multidimensional space. The mean vector marks the center of this cloud. This central point is crucial because it represents the "typical" or "representative" point for the data points within the cloud. The spread of the cloud in different directions is controlled by the standard deviation, which can vary across the dimensions.
Mathematically, an MND is like a higher-dimensional version of a normal distribution. Each dimension is independent and follows a standard normal distribution (mean of 0, variance of 1). This specific configuration is what sets a standard MND apart from other multivariate normal distributions.
By using a standard MND, we can constrain the latent space, which is a useful technique in certain applications. This helps to remove unwanted areas or "noise" from the latent space, as demonstrated in the AE (Autoencoder) latent space model.

Imagine a bivariate normal distribution. This is a statistical model that describes the probability of two variables occurring together. In this case, the variables are the mean and standard deviation.
For an image dataset, the mean vector is a point in the latent space (a multi-dimensional space). When you process an image, an encoder maps it to this mean vector. This mean vector represents the center of the distribution for that specific image in the latent space.
The standard deviation vector also lives in the latent space. It defines the spread or width of the distribution around the mean.
In a VAE framework, each input image has its own unique distribution. This distribution is characterized by its mean vector and standard deviation vector. The mean vector indicates the central point, while the standard deviation vector determines how spread out the distribution is.

For a MNIST dataset, the latent space might look like a multi-dimensional space where each point represents a different digit. When a random input is given to a VAE, it will output an image of a digit.
To ensure that the latent space distribution stays close to a standard normal distribution, we use the KL divergence loss function. This helps to align the mean and variance of the training data's latent space with a standard normal distribution.
The latent space vector is calculated using the formula Z = μ + (σ × ϵ), where ϵ is a standard normal distribution. The encoder generates the mean and standard deviation for each latent variable. Then, it samples from this distribution to create a latent vector, which is passed to the decoder for reconstruction.
Instead of directly outputting latent space vectors, the VAE's encoder outputs parameters of a predefined distribution for each input. The VAE then applies a constraint on this distribution, forcing it to be a normal distribution. This helps to regularize the latent space.

In a VAE, the encoder outputs parameters of a probability distribution (often a Gaussian). These parameters are used to sample latent variables. However, the sampling process itself is non-differentiable. This means it's difficult to determine the exact shape or "curve" of the sampled latent distribution. This makes it challenging to backpropagate gradients during training, which is essential for optimizing the VAE's parameters.
A non-differentiable operation is a mathematical process that doesn't have a smooth curve at certain points. This means its rate of change can't be defined at those points. In machine learning, especially in gradient-based optimization, differentiability is crucial. These algorithms use gradients to update model parameters and minimize the loss. If a function is not differentiable, these algorithms can't be applied directly.

The reparameterization trick is a technique designed to address the issue of non-differentiability in the sampling process of Variational Autoencoders (VAEs). By introducing a deterministic transformation, it separates the random sampling from the learned parameters, allowing gradients to flow through the model during backpropagation. This is crucial for training VAEs effectively.
The reparameterization trick essentially makes the sampling process differentiable, similar to a Gaussian distribution. This enables us to use gradient-based optimization techniques to train the VAE.
Here's how it works:
- Instead of directly sampling from the mean and log variance (z_mean and z_log_var), we employ the reparameterization trick.
- We start by sampling a random value (epsilon) from a standard normal distribution with a mean of 0 and a variance of 1.
- We then adjust epsilon to have the desired mean and variance: z = z_mean + z_log_var*epsilon.
- This reparameterization trick ensures that all randomness is contained within epsilon, resulting in deterministic gradients. This means that gradients can flow backward through the layer during training, enabling efficient optimization.
- By keeping all randomness within epsilon, the partial derivative of the layer's output remains deterministic, independent of the random epsilon.
- Deterministic gradients are essential for backpropagation through the layer and training the neural network effectively.
KL Divergence is a metric that measures the difference between two probability distributions. The Evidence Lower Bound (ELBO) is the objective function optimized during training. It combines the reconstruction loss (how well the VAE can reconstruct the input) and the KL divergence (how close the latent distribution is to a standard normal).

Problem: To train a VAE, we need to generate samples and then use backpropagation gradient descent to adjust the encoder and decoder parameters. However, if the latent variable "Z" is computed randomly, backpropagation cannot estimate the derivative.
Solution: We use the reparameterization trick.
The reparameterization trick leverages the properties of a simple univariate normal distribution to make the backpropagation process possible. By using a deterministic transformation, we can ensure that the gradient can be calculated and used to update the model's parameters.

The VAE's loss function is composed of two objectives:
- Reconstruction: The VAE should be able to accurately reconstruct the input data from its latent representation.
- Latent Distribution: The latent space should be normally distributed.
The reconstruction loss involves an expectation operator because we are sampling from a distribution.
KL divergence measures the difference between two probability distributions. By minimizing KL divergence, we are adjusting the probability distribution parameters (mean and sigma) to match the target distribution more closely.
The VAE aims to minimize the Kullback-Leibler (KL) divergence between the approximate posterior distribution (learned by the encoder) and the true posterior distribution. This is combined with a reconstruction loss to ensure that the generated data is similar to the original input.

Comments
Post a Comment